ich bin beim Einlesen in das handling der Mobus-Tasks auf eine Ungereimtheit gestoßen.
Im Speziellen geht es darum, wann und in welcher Reihenfolge die Modbus-Tasks abgearbeitet werden.
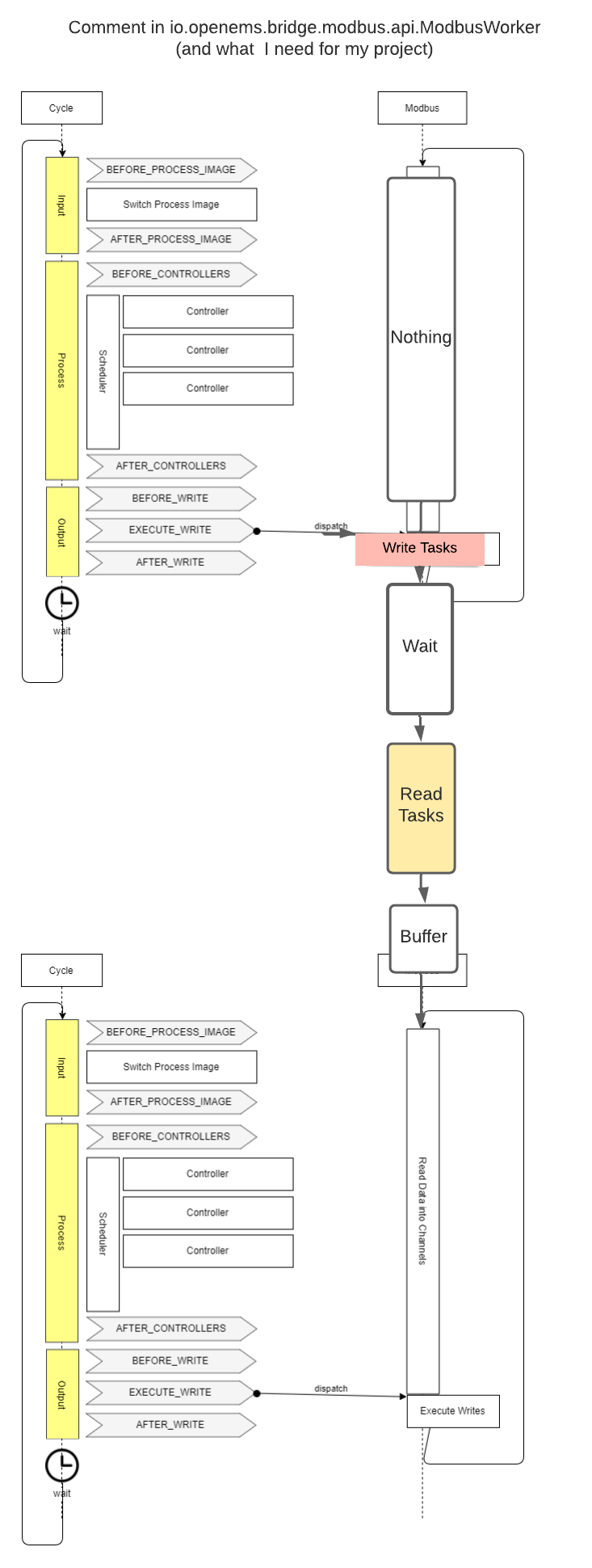
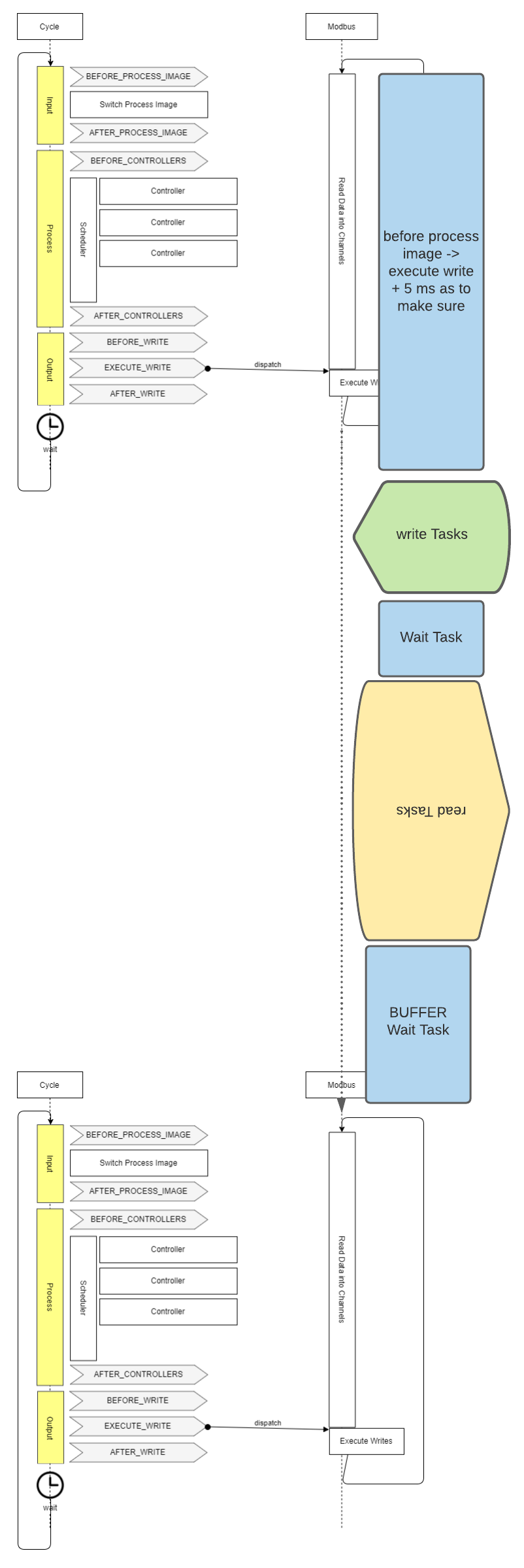
Um deutlich zu machen, was ich meine habe ich zwei Grafiken anhand des Bildes in der Dokumentation der Architektur erstellt.
Im Kommentar im ModbusWorker (ModbusWorker.java) steht es so beschrieben:
It tries to execute all Write-Tasks as early as possible (directly after the
TOPIC_CYCLE_EXECUTE_WRITE event) and all Read-Tasks as late as possible to
have correct values available exactly when they are needed (i.e. at the
TOPIC_CYCLE_BEFORE_PROCESS_IMAGE event).
Jetzt die Frage: habe ich da etwas falsch verstanden, oder passen der Kommentar und der Code micht zusammen, was sollte eigentlich passieren?
Im Allgemeinen ergibt die Abfolge: lesen → verarbeiten → schreiben ja am meisten Sinn. (also wie es beschrieben, aber nicht ausgeführt ist)
Und wie kann ich es auf möglichst einfach in den gewümschten Zustand bringen?
Wir haben jetzt mal versucht die Reihenfolge der Queue anzupassen. Im ersten Test hat es funktioniert.
Änderungen nur am Ende der onBeforeProcessImage().
danke für detaillierte Analyse. So wie du es beschreibst ist es sinnvoll - aus meiner Sicht schließen sich aber beide Ansätze nicht unbedingt aus.
Die Logik zwischen den Cycles sollte in beiden Analysen praktisch identisch sein. Die genauen Unterschiede zwischen “Wait → Read Tasks → Buffer” und “Reas Tasks → Wait” habe ich jetzt aber nicht im Code nachvollzogen.
Der Unterschied zwischen den beiden Bildern kommt nur dann zum Tragen, wenn mehr Modbus-Tasks ausgeführt werden müssen, als in die “Wait”-Zeit passen. In dem Fall müssen Tasks auch in der “Nothing”-Zeit ausgeführt werden. Nach meiner Erfahrung tritt das vor allem bei Modbus/RTU auf, wenn mehrere Geräte mit vielen Tasks auf dem gleichen RS485-Bus hängen. Insofern halte ich die Implementierung schon für sinnvoll und sie widerspricht nicht unbedingt dem Kommentar.
Leider muss ich aber auch zugeben, dass es für diesen Code keinen JUnit-Test gibt, so dass es relativ schwer ist nachzuvollziehen, was im Einzelfall genau passiert. Wenn wir uns also an ein Refactoring machen - was ich beführworte und gerne unterstütze - sollten wir das Test-Driven entwickeln, also erst einen JUnit-Test schreiben, der den gewünschten Ablauf in verschiedenen Szenarien beschreibt und dann den Code umbauen.
Sehe ich genau so, deshalb auch die Idee mit “so spät wie möglich lesen”. Das Problem ist eben, wenn es zu viele Tasks sind.
Der Unterschied in den beiden Ansäten liegt der Zeitverzögerung, wann die gelesenen Werte verarbeitet werden. Für viele Regelungsalgorithmen wäre natürlich so wenig Zeitverzug wie möglich sinnvoll.
Und der Unterschied tritt eben nicht nur auf, wenn die Wait-Time zu klein ist.
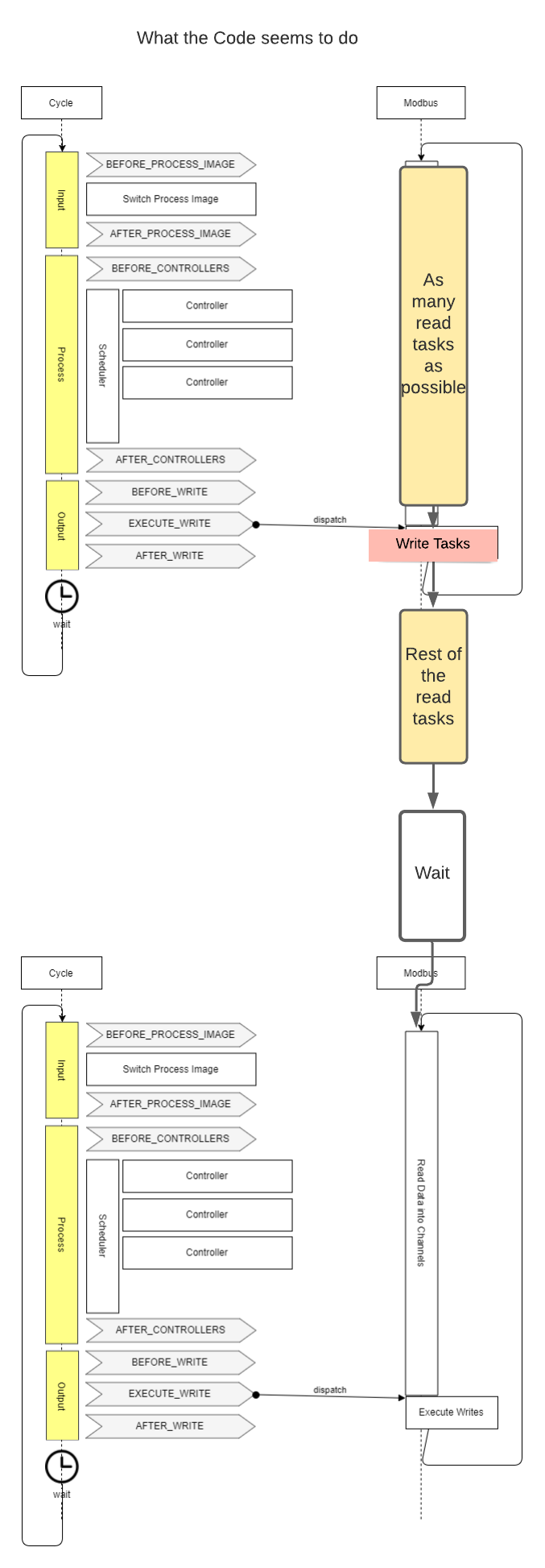
So wie ich den Code verstehe:
wird zuerst die Zeit zwischen BEFORE_PROCESS_IMAGE und EXECUTE_WRITE mit so vielen Modbus Read Tasks wie möglich befüllt. Das ist aber der schlechtestmögliche Zeitpunkt, weil so die Verzögerung bis zur möglichen Verarbeitung der Werte im nächsten Cycle maximal ist.
Danach wird die die Zeit nach dem EXECUTE_WRITE befüllt und zu guter letzt wird ein Wait-Task eingefügt um die Zeit bis zum nächsten Cycle zu überbrücken. Genau diese Zeit ist doch aber die Beste, um Werte auszulesen, da man so die aktuellsten Werte zum Verarbeiten bekommt.
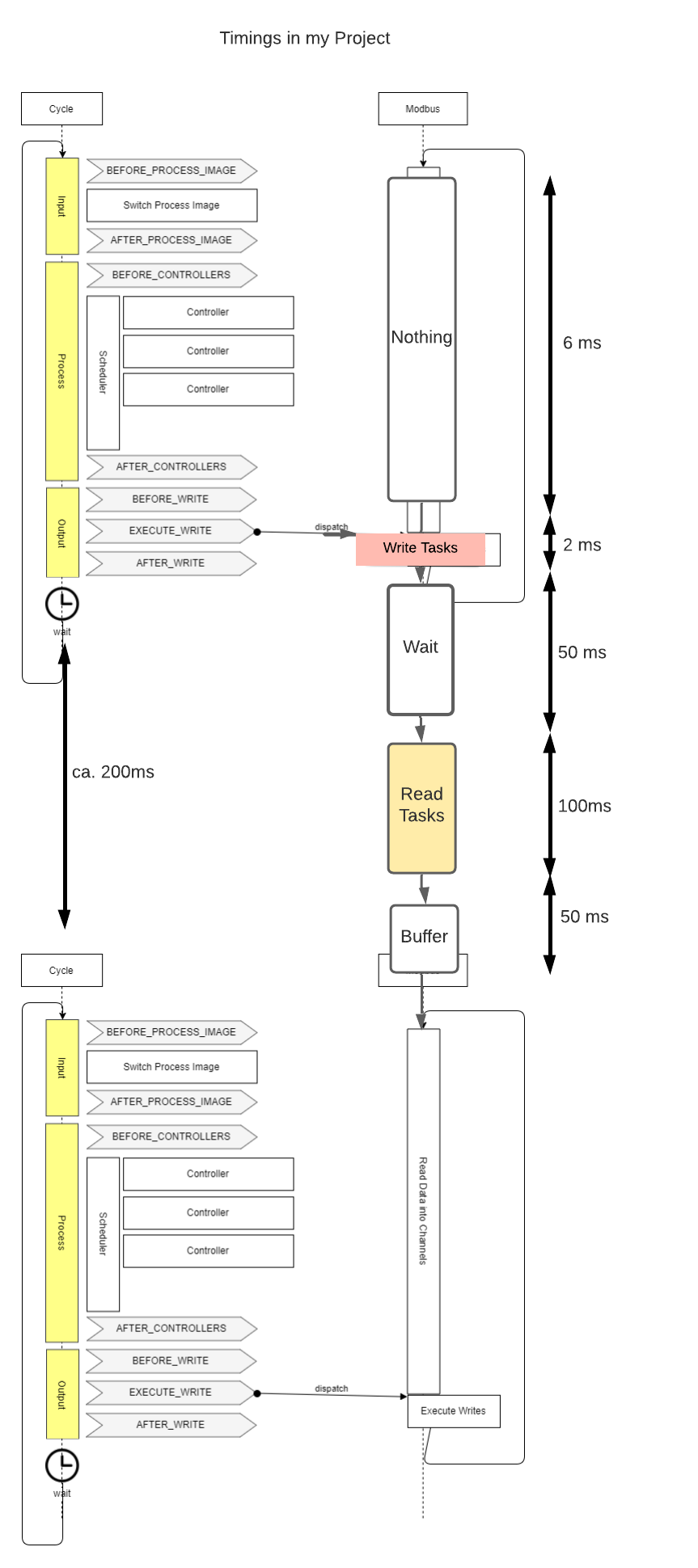
Ich habe das ganze mal mit den ungefähren Zeit in meinem Projekt dargestellt:
In meinem Fall bedeutet die momentane Lösung im ModbusWorker eine unnötige Verzögerung von ca. 150 ms, wenn die Read Tasks im “Nothing” Block ausgeführt werden.
ich habe die Thematik nochmal genauer analysiert. Dabei ist mir ein großer Irrtum in meinen vorherigen Überlgeungen aufgefallen.
Mein großer Fehler: Ich bin davon ausgegangen, dass die Modbus Write Tasks genau zu Zeitpunkt der Execute Write im OpenEMS begonnen werden. Dadurch habe ich meine Analysen des Netzwerkverkehrs (mittels Wireshark) falsch interpretiert.
Ich würde die Entwickler bitten, dass in den OpenEMS Docs klar zu stellen, weil es schon sehr irreführend benannt ist. (Oder den Code anzupassen, jenachdem was das eigentlich gewünschte Verhalten ist.)
Bei den jetzt folgenden Bildern bin ich mir relativ sicher, dass die diesmal stimmen. Ich habe dazu jeweils die Zeiten der OpenEMS Events (EXECUTE_WRITE, etc.) ausgeben lassen und mit den Zeiten der Modbuskommunikation aus Wireshark verglichen (und auch sichergesetllt, dass beide die gleiche Zeit verwenden)
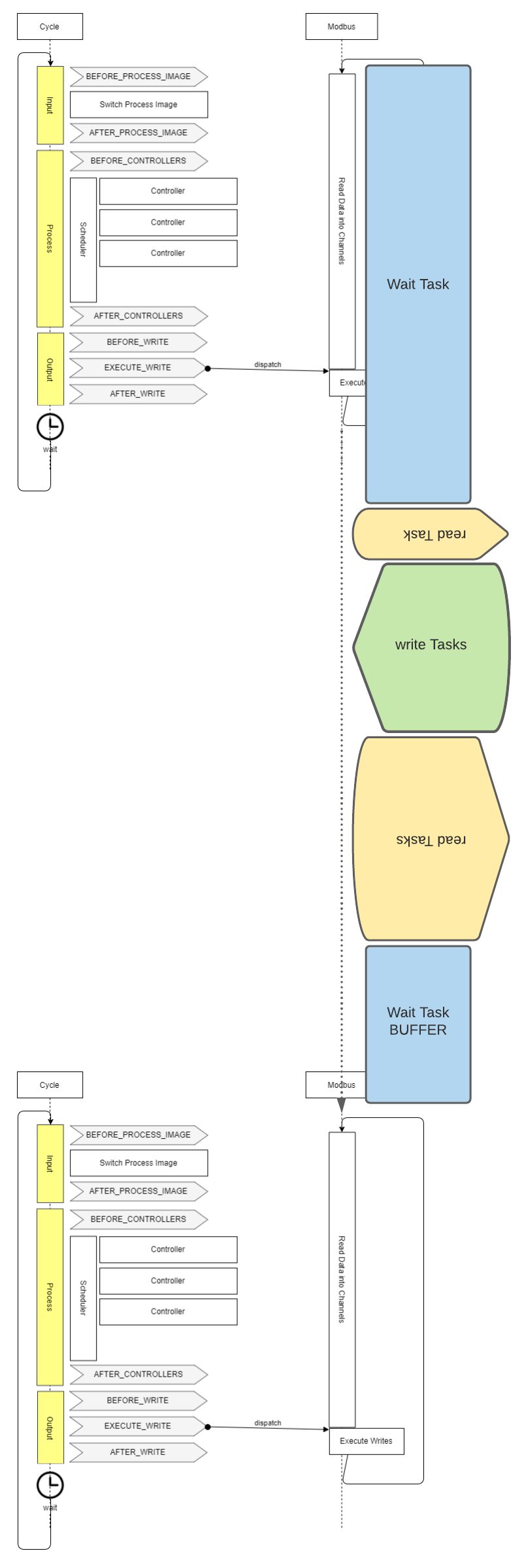
Die Modbuskommunikation wie sie in OpenEMS impelemtiert ist verläuft so:
Unter der Voraussetzung das der im Zyklus auzuführende Code nur wenige Millisekunden dauert und die Modbus Tasks bis zum nächsten Zyklus abgearbeitet werden können.
Dabei fällt auf, dass immer, auch wenn die Zeit zwischen BEFORE_PROCESS_IMAGE und EXECUTE_WRITE zu kurz für einen Modbus Task ist immer einer vor den Writes ausgeführt wird. Das liegt an folgendem Code:
Im ersten Durlauf der Schleife ist die durationOfTasksBeforeExecuteWriteEvent ja immer 0 und somit kleiner als die durationBetweenBeforeProcessImageTillExecuteWrite. Also wird immer ein Read Task zu beginn ausgeführt.
Zudem erschießt sich mir der Sinn davaon ohnehin nicht wirklich. Aus den in den Oben genannten Gründen mit den alten Messwerten (wobei das zugegebenermaßen vielleicht nicht in allen Anwendungen relavant ist).
Außerdem wird der Task dann ja, wie in meinem Bild von oben zu sehen, eben nicht zwischen den Events BEFORE_PROCESS_IMAGE und EXECUTE_WRITE ausgeführt, das es den Wait Task gibt.
Dieser wird eben ganz zu Anfang abgearbeitet, weil er ganz am Ende der Queue steht.
(Nebenbei bemerkt arbeiten Queues ja normalerweise nach dem FIFO Prinzip. Deshalb ist es etwas verwirrend, dass hier die Tasks am Ende zuerst ausgeführt werden:
Deshalb funktioniert auch die von mir hier vorher gepostete “Lösung” nicht)
Das für mein Projekt bessere Verhalten wäre das folgende (im Prinzip wie in den adneren Posts auch schon dargestellt).
Verändert ist hier vor allem der Eingefügte Wait Task, der Notwendig ist, damit die Write Tasks nicht direkt nach dem BEFORE_PROCESS_IMAGE ausgeführt werden und neue Write Werte erst durch die Controller berechnet werden können.
Das ist ja, so wie ich dich, Stefan, verstaden habe eigentlich auch das, was ihr eigentlich haben wollt (Abgesehen von den Tasks zwischen BEFORE_PROCESS_IMAGE und EXECUTE_WRITE).
Zumindest habe ich die Vermutung, dass alles, auch unabhängig von meinen speziellen Anforderungen, nicht so funktioniert, wie ihr es eigenlich haben wollt. Deshalb soltet ihr euch die Erstellung der Task Queue vielleicht nochmal anschauen.
Mein Momentaner Code, der zumindest grundlegend getestet ist sieht so aus, vielleicht hilft es ja wem:
/**
* This is called on TOPIC_CYCLE_BEFORE_PROCESS_IMAGE cycle event.
*/
protected void onBeforeProcessImage() {
// Measure the actual cycle-time; and starts the next measure cycle
long cycleTime = 1000; // default to 1000 [ms] for the first run
if (this.cycleStopwatch.isRunning()) {
cycleTime = this.cycleStopwatch.elapsed(TimeUnit.MILLISECONDS);
}
this.cycleStopwatch.reset();
this.cycleStopwatch.start();
// If the current tasks queue spans multiple cycles and we are in-between ->
// stop here
if (!this.tasksQueue.isEmpty()) {
return;
}
// Collect the next read-tasks
List<ReadTask> nextReadTasks = new ArrayList<>();
ReadTask lowPriorityTask = this.getOneLowPriorityReadTask();
if (lowPriorityTask != null) {
nextReadTasks.add(lowPriorityTask);
}
nextReadTasks.addAll(this.getAllHighPriorityReadTasks());
long readTasksDuration = 0;
for (ReadTask task : nextReadTasks) {
readTasksDuration += task.getExecuteDuration();
}
// collect the next write-tasks
long writeTasksDuration = 0;
List<WriteTask> nextWriteTasks = this.getAllWriteTasks();
for (WriteTask task : nextWriteTasks) {
writeTasksDuration += task.getExecuteDuration();
}
// plan the execution for the next cycles
long totalDuration = readTasksDuration + writeTasksDuration;
long totalDurationWithBuffer = totalDuration + TASK_DURATION_BUFFER;
long noOfRequiredCycles = ceilDiv(totalDurationWithBuffer, cycleTime);
// Set EXECUTION_DURATION channel
this.parent._setExecutionDuration(totalDuration);
// Set CYCLE_TIME_IS_TOO_SHORT state-channel if more than one cycle is required;
// but only if SlaveCommunicationFailed-Channel is not set
if (noOfRequiredCycles > 1 && !this.parent.getSlaveCommunicationFailed().orElse(false)) {
this.parent._setCycleTimeIsTooShort(true);
} else {
this.parent._setCycleTimeIsTooShort(false);
}
long durationOfTasksBeforeExecuteWriteEvent = 0;
int noOfTasksBeforeExecuteWriteEvent = 0;
for (ReadTask task : nextReadTasks) {
if (durationOfTasksBeforeExecuteWriteEvent > this.durationBetweenBeforeProcessImageTillExecuteWrite) {
break;
}
noOfTasksBeforeExecuteWriteEvent++;
durationOfTasksBeforeExecuteWriteEvent += task.getExecuteDuration();
}
// Build Queue
Deque<Task> tasksQueue = new LinkedList<>();
// ******* von mir raus genommen und später eingefügt *******
// Add all write-tasks to the queue
// tasksQueue.addAll(nextWriteTasks);
// Add all read-tasks to the queue
for (int i = 0; i < nextReadTasks.size(); i++) {
ReadTask task = nextReadTasks.get(i);
// if (i < noOfTasksBeforeExecuteWriteEvent) {
// // this Task will be executed before ExecuteWrite event -> add it to the end of
// // the queue
// tasksQueue.addLast(task);
// } else {
// // this Task will be executed after ExecuteWrite event -> add it to the
// // beginning of the queue
// tasksQueue.addFirst(task);
// }
// ************ meine Code Veränderung ****************************************
// add all read Tasks to the Beginning of the List -> will be executed after Write Tasks
tasksQueue.addFirst(task);
}
// Add a waiting-task to the end of the queue
// long waitTillStart = noOfRequiredCycles * cycleTime - totalDurationWithBuffer;
long waitTillStart = noOfRequiredCycles * cycleTime - totalDurationWithBuffer - (this.durationBetweenBeforeProcessImageTillExecuteWrite + 5);
tasksQueue.addLast(new WaitTask(waitTillStart));
// ********** von mir hier eingefügt **********
// Add all write-tasks to the queue
// will be executed at the start, wait task after that
tasksQueue.addAll(nextWriteTasks);
// ************ auch von mir eingefügt **********************
// Wait Task, sodass genug Zeit bleibt die neuen Schreibwerte auszurechnen
tasksQueue.addLast(new WaitTask(this.durationBetweenBeforeProcessImageTillExecuteWrite + 5));
// Copy all Tasks to the global tasks-queue
this.tasksQueue.clear();
this.tasksQueue.addAll(tasksQueue);
}
So, dass war jetzt viel Text. Gratulation, wenn du bis hier gelsesen hast.
Ich würde mich über eine Antwort freuen, ob du, Stefan, oder auch jemand anderes meine Analysen nachvollziehen kann und mir zustimmt. Besteht ja natürlich auch die Möglichkeit, dass ich wieder einen Fehler gemacht habe.
ich bin hier eine kurze Rückmeldung schuldig. Die Analyse ist schlüssig und sehr gut. Vielen Dank dafür! Sie könnte (und sollte) die Grundlage dafür sein, diesen Algorithmus nochmal strukturiert und umfassend getestet (mit JUnit-Tests, wie ich oben schon geschrieben habe) neu zu implementieren.
Ich komme zur Zeit leider nicht dazu das aktiv anzugreifen. Falls du (oder jemand anderes) dazu einen Pull-Request starten willst oder eine andere Idee hast, wie wir in dem Thema weiter kommen, werde ich mich natürlich gerne aktiv daran beteiligen.
ich habe mich mal mit der Ausführung der Modbus Read- und Write-Tasks beschäftigt. Falls du noch an dem Thema dran bist, würde mich deine Meinung zu diesem Pull-Request interessieren:
Der Pull-Request ist mittlerweile ziemlich komplett und ausgiebig auf meinem eigenen System getestet. Ich freue mich über jegliches Feedback, bevor ich ihn in das nächste Release mit aufnehme: